
Cloudera All-In-One
As part of my day job I’ve been partnering with the Cloudera Data Platform to create content for IBM Developer. Such as A deep dive on integrating Cloudera Data Platform and IBM Cloud Pak for Data and Using Cloudera’s SQL Stream Builder to talk to IBM Cloud.
But in each of those cases I was using a production-like cluster to test and integrate with IBM products. Which, isn’t a bad thing but did take some time to get things spun up and configured properly.
There was a need to get an instance of Cloudera Data Platform with as small a footprint as possible. That’s when I was told about the SingleNodeCDPCluster project.
Check out the https://github.com/fabiog1901/SingleNodeCDPCluster project
Below are my notes as I worked my way getting the project up and running on a single VM on IBM Cloud, and integrating it with Cloud Pak for Data.
IBM Cloud: Create a virtual machine
I spun up a 16 vCPU x 64 GB RAM VM on IBM Cloud, with CentOS 7.9 as the OS. I also made sure to have a 100 GB disk instead of the default 25 GB.
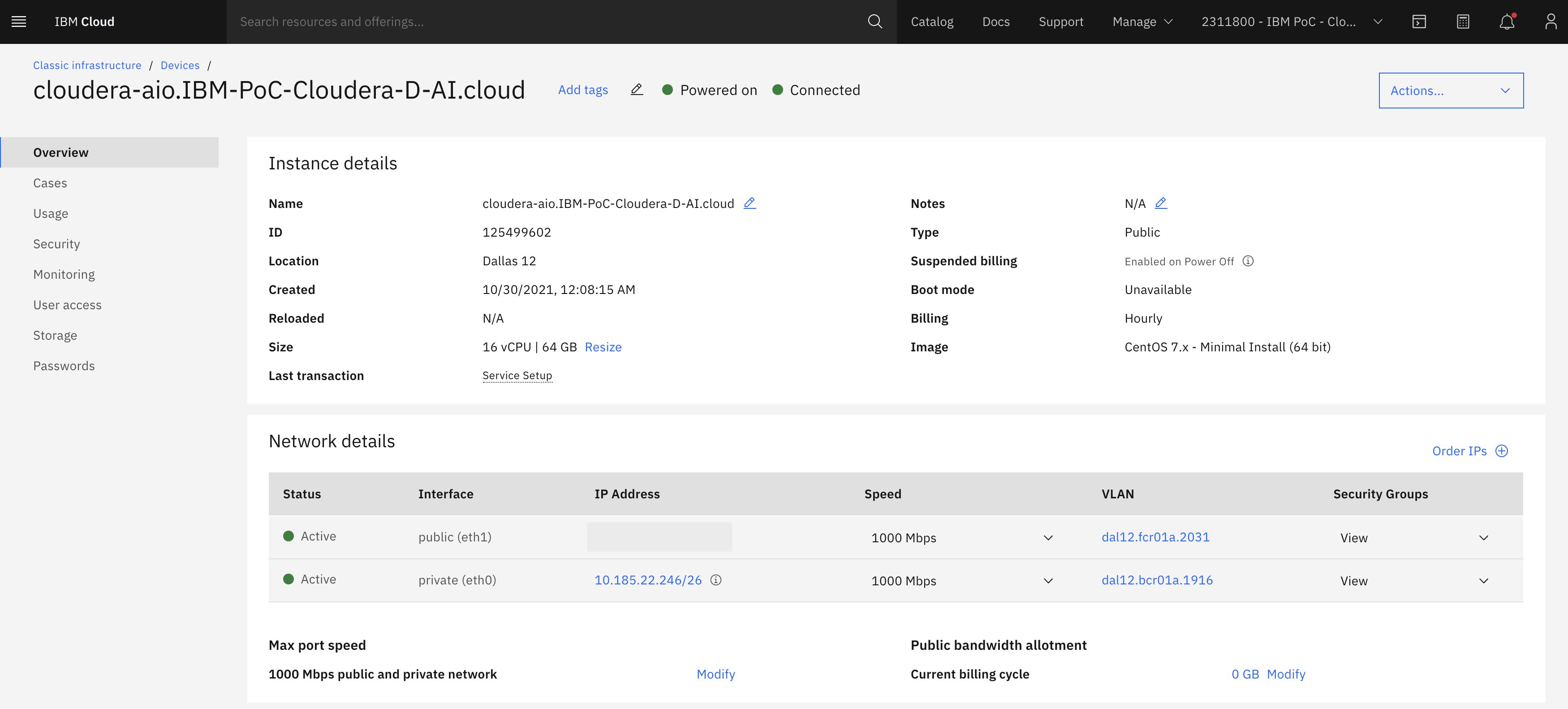
I ssh’ed into the machine and ran the following, which kicked off a long process to install CDP.
yum install -y git
git clone https://github.com/fabiog1901/SingleNodeCDPCluster.git
cd SingleNodeCDPCluster
./setup.sh gcp templates/base.json
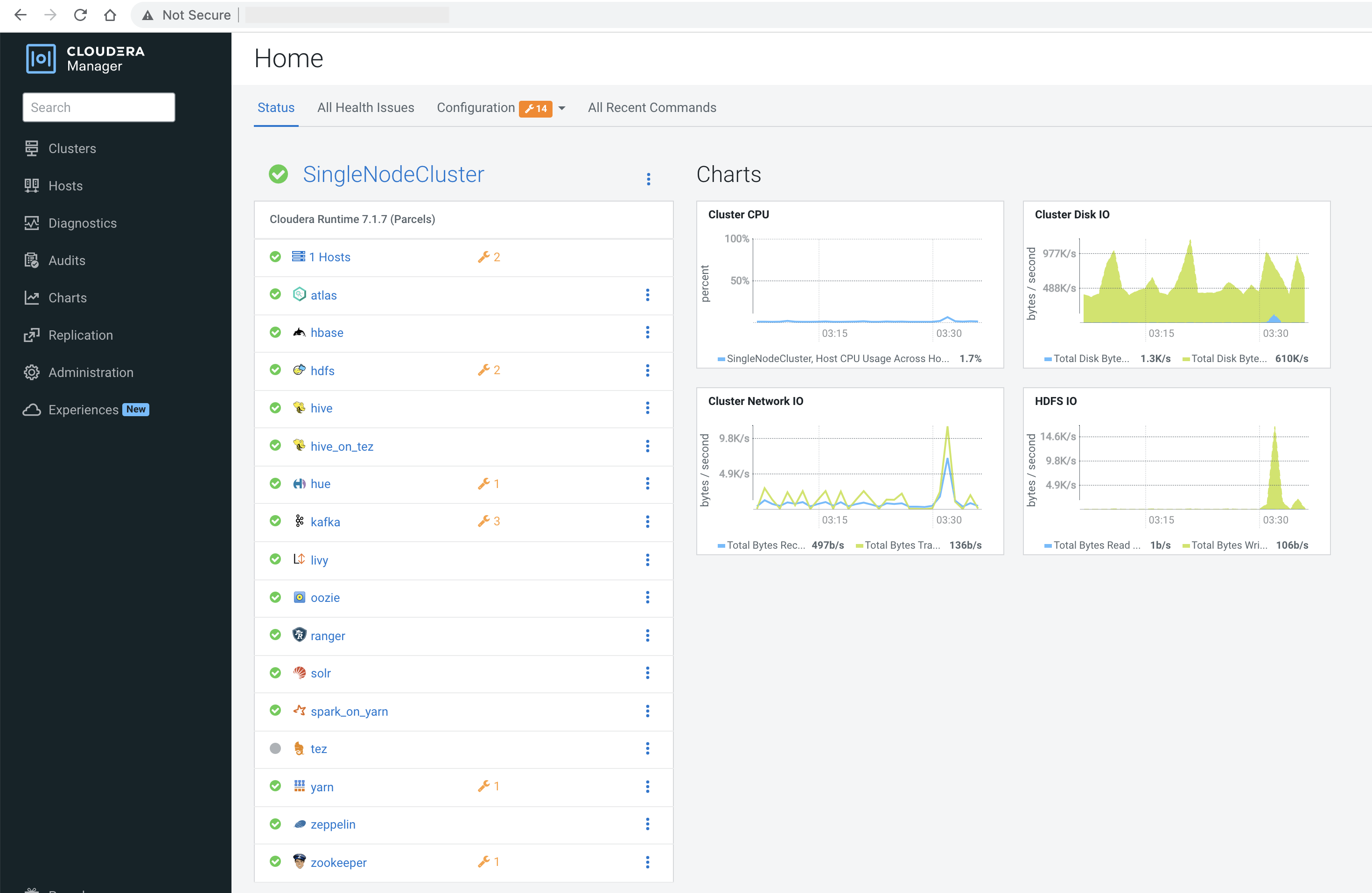
Cloudera Data Platform: Log into Cloudera Manager
You can get to Cloudera Manager by going to http://<public-IP>:7180. The credentials are admin/admin.
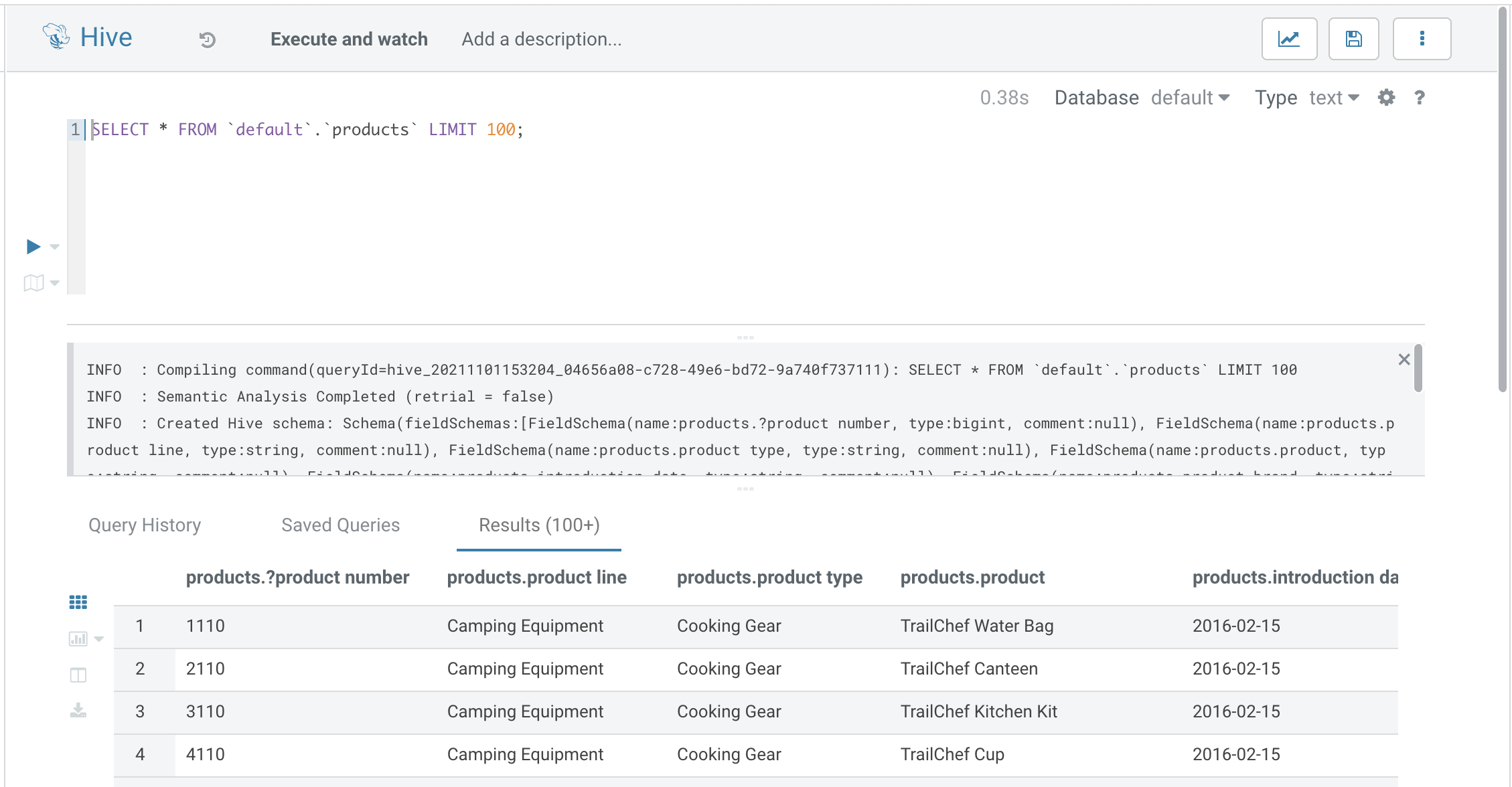
Cloudera Data Platform: Load data with Hue
Since we’re hoping to use this for a workshop we want to use GUIs as much as possible. So to load data I decided to use Hue. Just upload the CSV file to HDFS and then load it into Hive. It’ll pick up the first row as the column header and detect it’ll be comma separated.
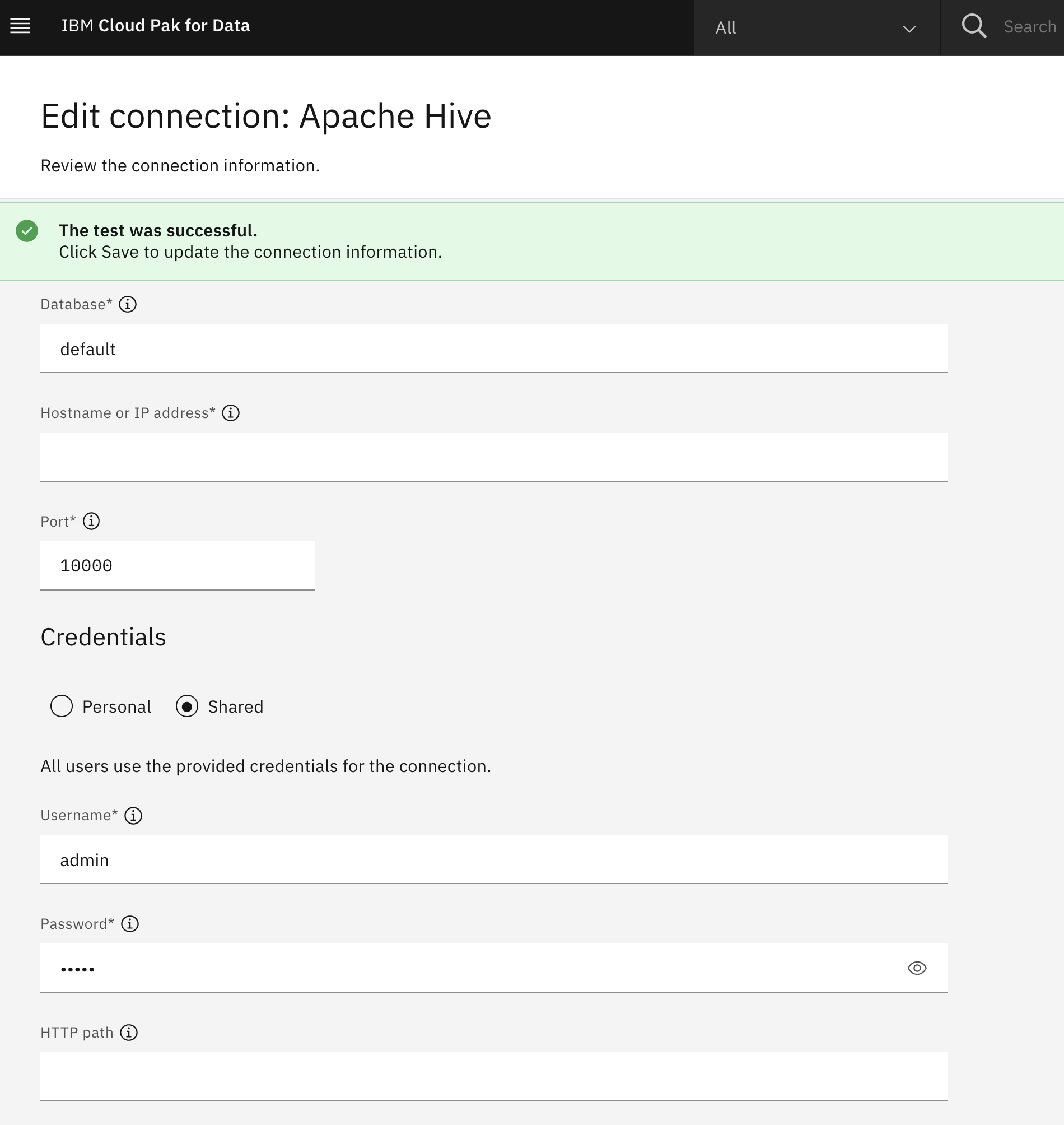
Cloud Pak for Data: Create a connection
In Cloud Pak for Data go to the Connection Manager, choose to create a new one, select Apache Hive. Punch in the public IP address, port 10000, and the admin credentials.
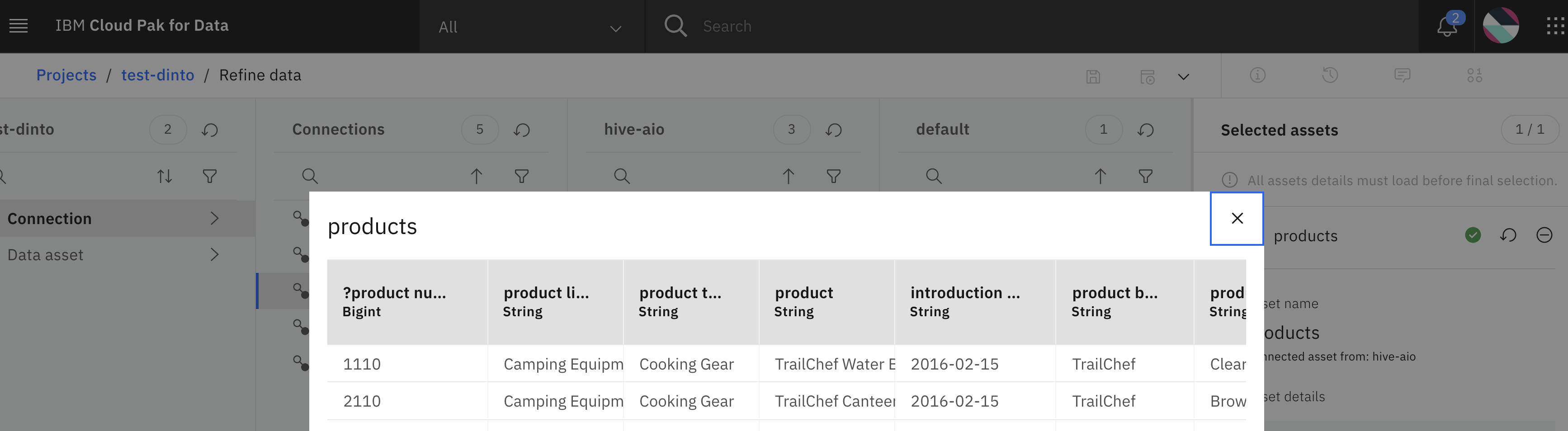
Cloud Pak for Data: View the data with Data Refinery
Create a new project, choose a new Refine Data flow, select the new connection, view the data.
Gotchas
-
Everything worked well except my package distribution failed. It was due to some networking bits on the IBM Cloud side. I followed these steps to get around it.
-
Two things that aren’t included: 1. Impala, and 2. Knox.
-
Check out Ali Bajwa’s Scripts too.