
Steve and JJ’s duct tape and bailing wire approach to managing IBM’s public GitHub org
JJ (his blog) and I have teamed up to bring some order to the chaos that was managing the IBM public GitHub organization. Manging the IBM public GitHub org was never a priority for any one team, but JJ and I saw this as an opportunity to solve a few interesting problems. So we went to work.
The “before” statePermalink
- Manually invited people (we had a short node javascript app that someone would run monthly on their laptop to do batch invites)
- Manually created repos (we had a home brewed CLI at one point, but still manual)
- Never archived any repos
- Never removed folks from the org (even if they left IBM and had admin rights on repos!)
- We had an app that “mapped” or linked someone’s GHE or GH account
The “TODO” listPermalink
We jotted down a bunch of the stuff we wanted to automate or make easier, here’s a quick snapshot. Predicably, it’s a lot of the stuff we had to manually do earlier, like create repos or invite new users.

We took stock of what tools were available to us, not much. A web app that mapped GHE accounts to public GH accounts and a handful of javascript apps that one of the admins used to run manually every now and then.
The “after” statePermalink
We ended up accomplishing four keys tasks that helped knock a bunch of items off the TODO list:
- improving the account mapper app to invite users as soon as they linked their account
- creating bash scripts that we run monthly using Jenkins (more on that later)
- creating a serverless app that handled new repo requests
- creating a dashboard that is updated daily and hosted on github pages
The toolsPermalink
We ended up using a variety of tools to accomplish all our tasks. We went heavy on Python and Bash given our background, but sprinkled in some Node for good measure.

Tool 1: Account mapper (Node.js on Cloud Foundry and Cloudant NoSQL Database)Permalink
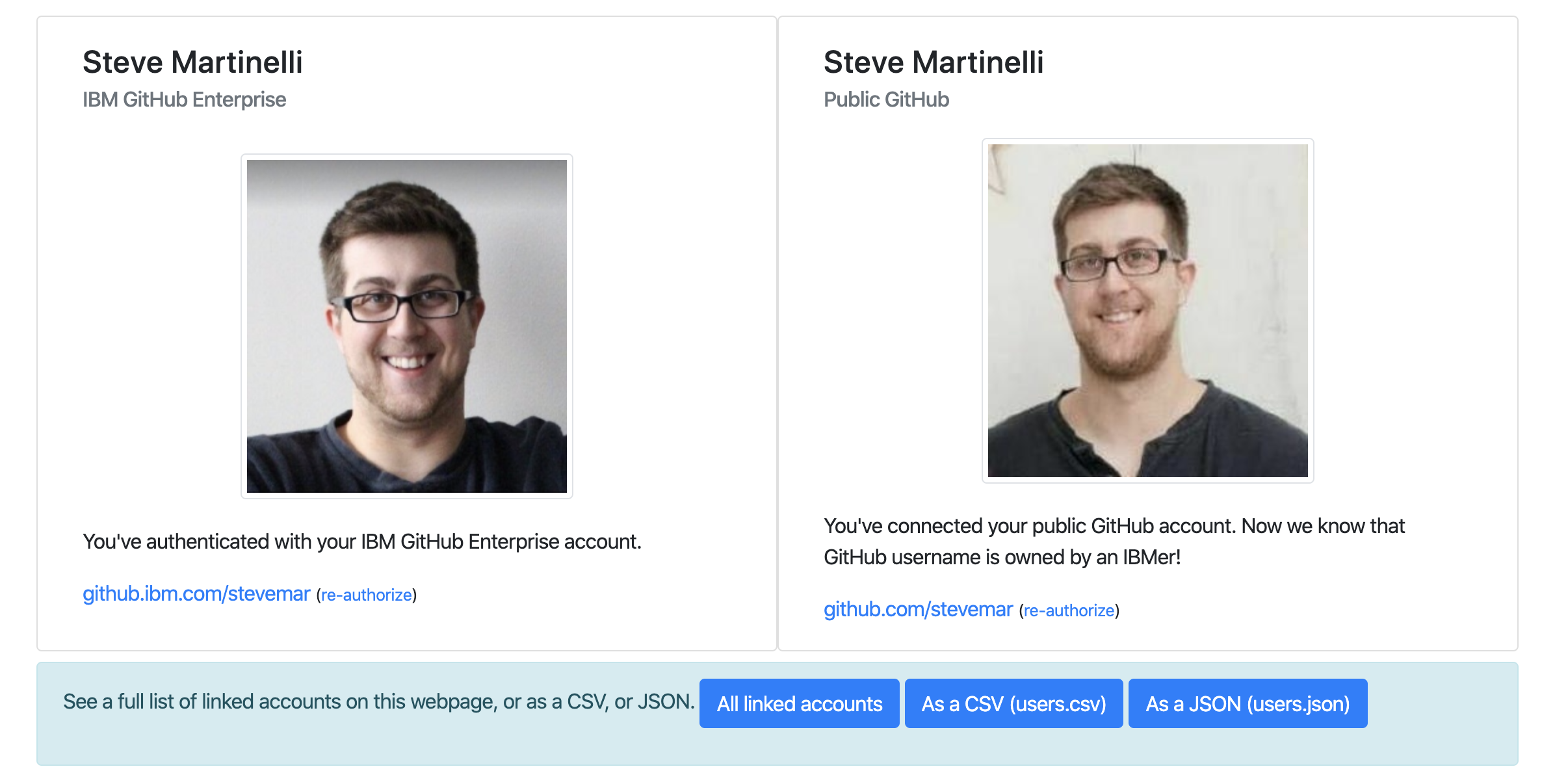
The flow of this is a user authenticates with their GitHub Enterprise and their public GitHub accounts and that relationship is saved to a Cloudant database. The web app and database are deployed to our internal cloud that can communicate with both outside and internal networks.
Credit for creating the app back in 2017 goes to @rmg and Ryan was kind enough to coach me through a few patches to the repo.
So why do we use this? a few reasons.
-
Originally this was made to just get an understanding of how many IBMers were involved in Open Source.
-
Newly added: Automatic invitations. Upon mapping a GHE account to a GitHub account an invite to join the public IBM org is sent out to the mapped GitHub account. This was one less manual task JJ and I to do.
-
Newly added: Employee verification. We recently started to persist employee status in the database. This is confirmed by grabbing the IBM email address associated with the GHE account and checking against our internal LDAP.
We use the data saved in our database as the source of truth for a few scripts that are run bi-weekly, see the next section for more details.
Tool 2: Admin scripts (Bash and Jenkins)Permalink
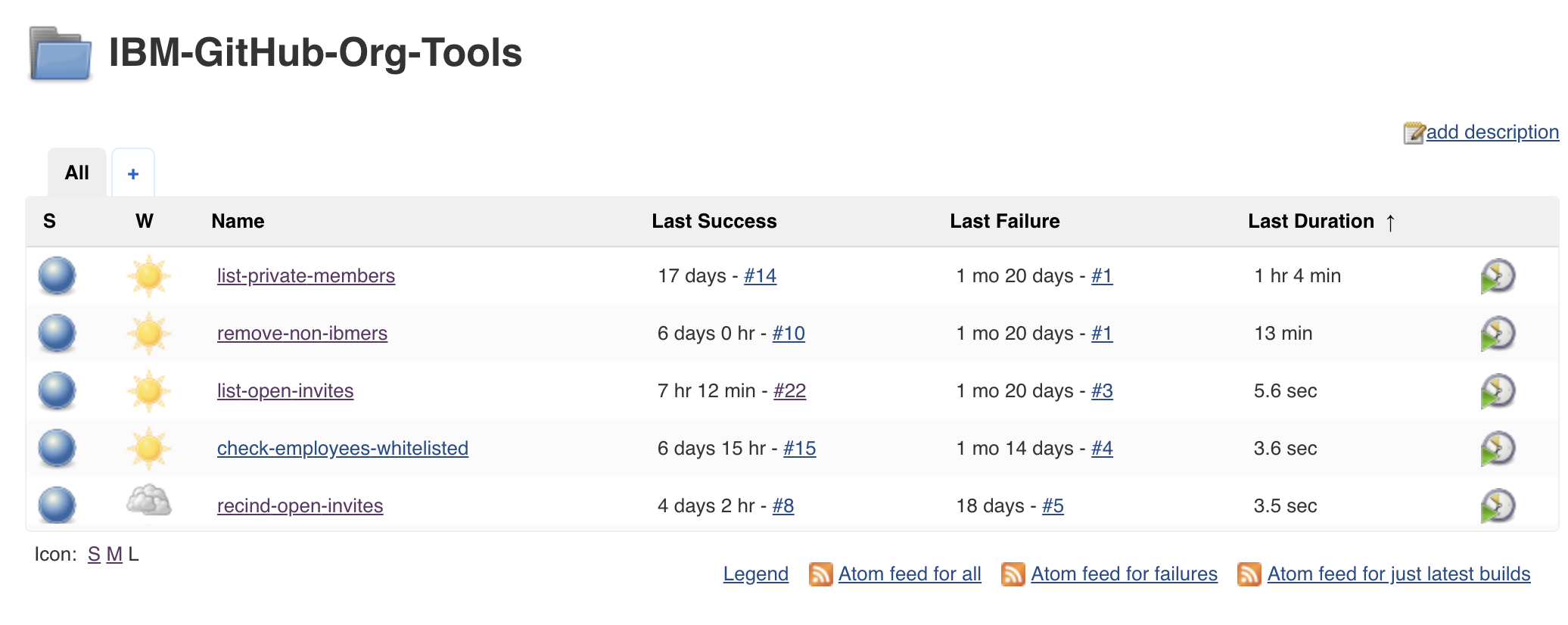
There were certain tasks that needed to be run on an internal, so we made use of an existing Jenkins deployment that could communicate with again internal and external networks. So, what do we run on Jenkins?
Given JJ’s sys admin background, it was very easy to use bash for our purposes, so we have a few shell scripts that:
- Email all IBM org members that have their membership set to “Private”, politely asking them to set it to “Public”.
- Remove former IBMers from the IBM org.
- Email folks with open invitations that have not been accepted.
- Rescind open invitations if they’ve been open for more than 30 days.
Tool 3: Request a repo bot (Python and Serverless)Permalink
This has already been written about on IBM Developer: https://developer.ibm.com/tutorials/github-task-automation-with-serverless-actions/
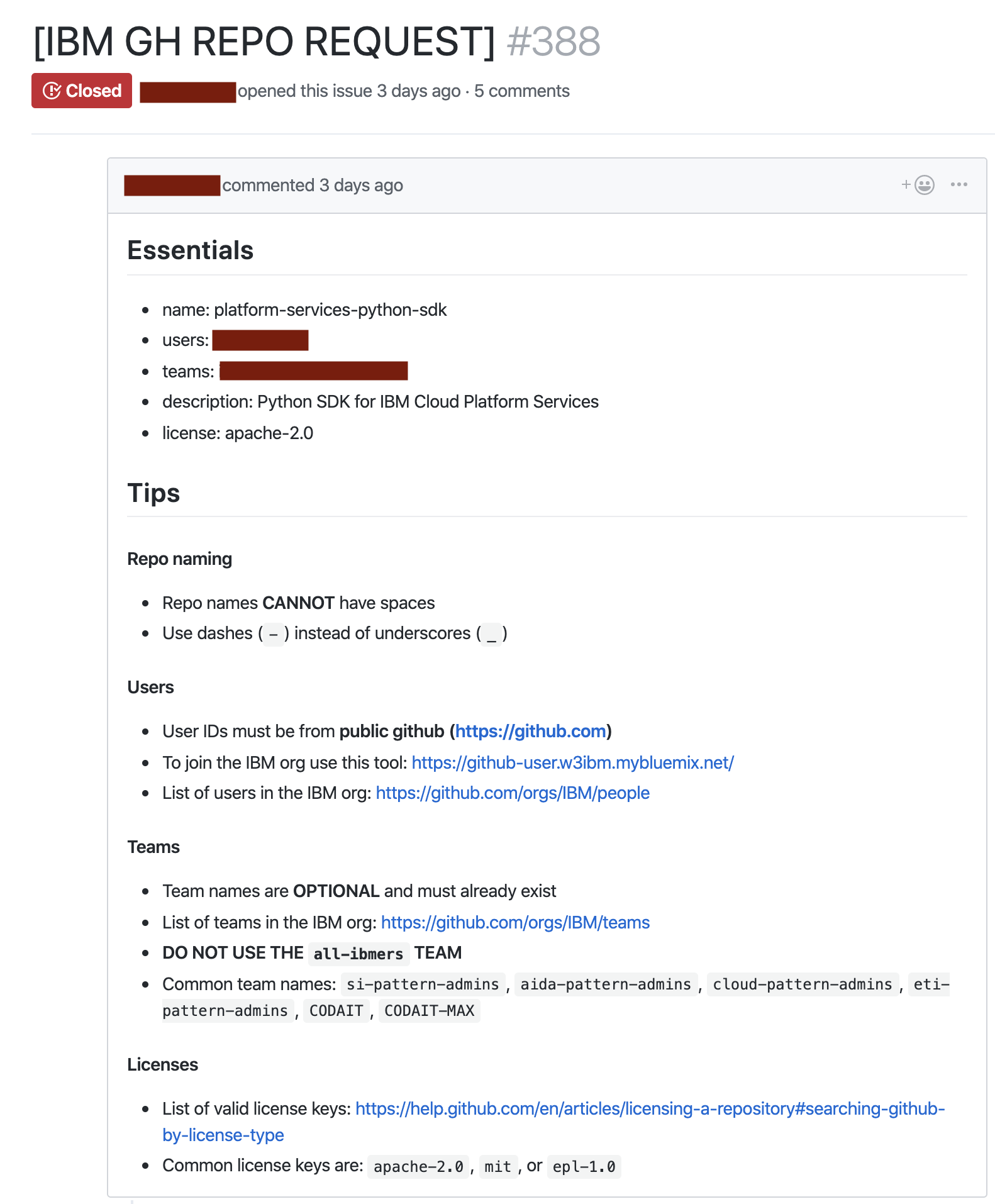
Requesting a new repo was probably 75% of the requests that I was fielding, it needed to be automated. Of course, as I was looking aorund at serverless technologies I felt the urge to scratch this itch. So I ended up creating a serverless action that reacts to new issues (and issue edits) for a specific repository. There are automated checks that post results in comments for the issue that give the originator some feedback, like “the user doesn’t exist” or “the user specified is not in the org, use the account linker…”.
Overall, our “bot” (it’s not really a bot, but it sounds fun) has fielded over 350 requests in around 6 months with pretty positive feedback.
Tool 4: Org Health Dashboard (Python and GitHub Pages)Permalink
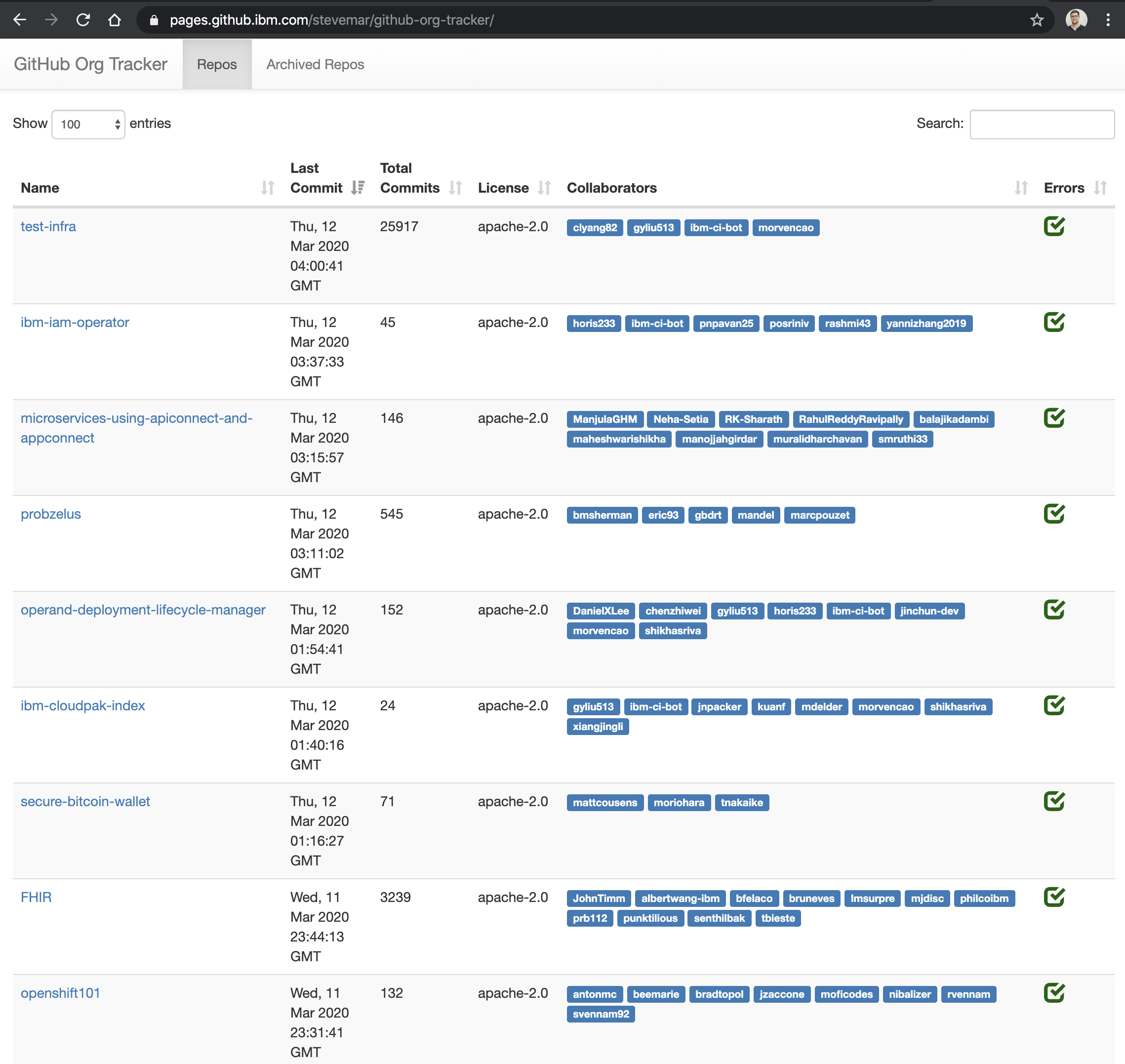
I needed a quick dashboard to find specific information about the repo. GitHub provides all this information but it’s really handy to have it all in one place that is easily searchable and sortable, rather than going into each individual repo. And yes, we looked at tools like repolinter but we needed something that provided GitHub specific status, not just any git repo stats. Things like, maintainers of the repo or if a repo is archived or not. Also, it was rather frustrating that the CLI didn’t support machine readable output (like JSON or YAML) by default.
The way this tool works is by running with Travis CI a nightly job that calls a python script to get all the data, it’s then saved in a YAML and using Jinja is transformed into HTML. It’s all checked into a github repo and viewable with GitHub pages. I have a version you can find online in my spog repository.
FinPermalink
Is this perfect? Not by a long shot. But it’s significantly better than where we were, and for that, we’re happy.